
以 DeepSeek-R1 为代表的强化学习范式,近期在语言模型领域掀起了一次 “推理革命”。
最近,港中文联合清华团队正式发布了首个将 “R1 范式” 系统性落地到视频推理领域的模型 ——Video-R1。不仅将强化学习算法从 GRPO 升级为更懂 “时间” 的 T-GRPO,还首次打通了图像 + 视频的混合训练路径,搭建了两个高质量数据集,真正让模型在视频中学会了 “深度思考”。

更令人惊讶的是:在李飞飞团队提出的 VSI-Bench 这一权威视频空间推理测试中,Video-R1(仅 7B 参数)竟然战胜了 GPT-4o!
目前,研究团队已经将全部代码、模型权重、数据集一并开源,视频推理的 “R1 时刻”,真的来了。
一、两大挑战亟待解决
视频理解,堪称 AI 领域的 “高阶技能”。模型不仅要识别画面中的物体,还要分析动作的前后逻辑。然而,现有的多模态大模型(MLLMs)在视频推理上存在两大难题:
时间建模不足:很多模型只会 “看单张截图”,忽略视频的时间顺序,导致推理错误。
高质量数据稀缺:现有的视频数据集大多只教 AI “认东西”,缺乏需要复杂推理的问题。
二、核心创新:新算法 + 混合数据,双管齐下
为了解决问题,Video-R1 团队祭出两大 “杀手锏”:
算法升级:T-GRPO
核心思想:让 AI 对比 “正常顺序视频” 和 “打乱顺序视频” 的表现,只有前者正确率更高时才给奖励。
效果:逼着 AI 学会 “看剧情发展”,而不是单帧 “蒙答案”。就像老师通过对比学生看正常电影和乱序片段的表现,来奖励真正理解故事的学生。
数据策略:图像 + 视频混合训练
图像数据(如数学题、图表题):教 AI 基础的逻辑推理能力。
视频数据(如物理实验、日常场景):训练时间推理能力。
数据集:团队构建了 26 万条混合数据(Video-R1-260k),涵盖数理、空间、常识等多种题型。
三、实验成果:7B 小模型表现惊人
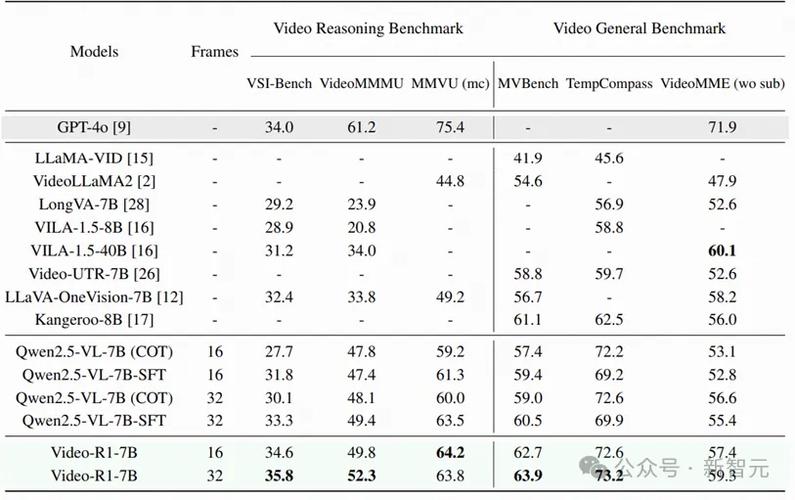
团队在 6 大视频推理基准测试中验证效果,结果惊人:
VSI-Bench(空间推理):Video-R1-7B 准确率 35.8%,超过 GPT-4o 的 34%。
VideoMMMU(知识推理):52.3% 准确率,远超同类模型。
通用视频理解(如 MVBench):性能全面提升。
强化学习(RL)是灵魂:仅用 1000 步 RL 训练,模型就从 “死记硬背” 进化到 “灵活推理”。
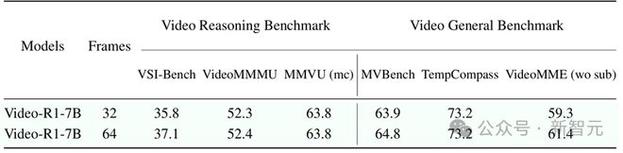
帧数越多越好:输入视频帧从 16 帧增加到 32 帧后,性能显著提升,说明 “看全片” 很重要!
四、有趣发现:“顿悟时刻”
在训练中,模型偶尔会表现出类似人类的 “自我反思” 行为:
例子:先给出一个答案,中途发现矛盾,重新分析视频帧,最终修正结论。
意义:这说明 AI 并非机械执行,而是在 “动脑子”—— 像学生做题时反复检查步骤!
虽然成果亮眼,但仍有改进空间:
处理长视频:当前模型最多看 32 帧,未来需支持更长的 “追剧模式”。
动态控制回答长度:避免 AI “啰嗦” 或 “过于简略”。
更大规模训练:目前 RL 训练仅 1 千步,潜力还未完全释放!








发表评论